

1 Introduction
Based on a letter from Diderot (1977), the ‘Molyneux problem’ (Eilan, 1993; Locke, 1975; Meltzoff, 1993; Morgan, 1977) raises the intriguing question of whether a person born blind would immediately recognize the shape of a sphere/cube by sight were their sight suddenly to be restored (presuming that these shapes had been experienced tactually prior to recovering sight). The question has long remained a lively theoretical debate amongst philosophers (e.g., Campbell, 1996; Evans, 1985; Green, 2021, 2022; Levin, 2008, 2018; Van Cleve, 2007), with early commentators putting forward opposing answers.1 The philosopher John Locke, as well as Molyneux himself, were both convinced that the question had to be answered negatively (Bruno & Mandelbaum, 2010); in contrast, Leibniz replied in the affirmative, although the reasons behind the latter’s position are not entirely clear. The disagreement has stimulated further discussion amongst a wide range of readers and commentators (Ehli, 2020; Glenney, 2012). One possible explanation here involves considering shape representations as purely formal and modality-independent schema that isomorphically map onto the shapes that are perceived, thus providing the tactile and visual representations with a common underlying structure and the perceiver with a common feature with which to recognize the shapes (Glenney, 2012). Alternatively, however, McRae’s (1976) analysis sets Leibniz’s answer to Molyneux’s question in terms of the possibility of translating between different expressions that target the same perceptual object from different sense modalities (see also Spence & Di Stefano, 2023). Finally, one could put forward the existence of an Aristotelian common sense (Owens, 1982), as Leibniz himself appears to suggest,2 thus allowing perceivers to process the information about a limited set of sensory qualities, including shape, through their different senses (see Spence & Di Stefano, 2024).
The most rigorous empirical research to have been published in recent years suggests that shape information is not immediately given by the perceptual array when those individuals who have been blind since birth (namely, congenital cataract patients) have had their cataracts surgically removed (Held et al., 2011). While it is certainly true that matching appears to improve markedly over a matter of days, such observations nevertheless argue against crossmodal matching on the basis of phenomenal quality, at least in the case of shape perception (cf. Campbell, 1996), on differences in the phenomenal quality of the visual and tactile experience of shape). Indeed, such findings can be taken as arguing against the suggestion that shape information is one of the objective properties that is coded amodally (Spence & Di Stefano, 2024). Note here also that the senses of touch and vision only actually provide redundant information about the shape and size of objects over a very small range of stimuli anyway, and that most of the objects we see (such as planets and skyscrapers etc.) cannot be felt.3
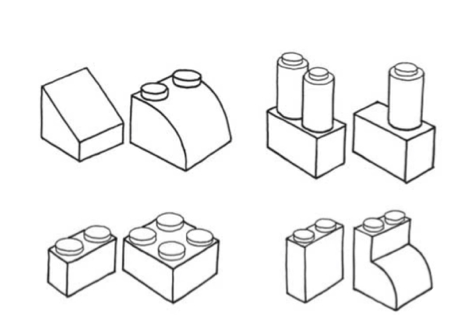
Held et al. (2011) examined cross-modal recognition in a group of five participants who had recently been treated for congenital blindness. The participants first saw or felt a sample 3D Lego-like shape (see Figure 1). Next, two test shapes were presented, with the participants instructed to discriminate which of the test shapes matched the sample (thus meaning that chance level performance was 50% correct). Twenty shapes pairs were used in this study. Performance was compared across three conditions: visual–visual, where the sample and test shapes were all presented visually; tactual–tactual, where all of the shapes were presented tactually; and tactual–visual, where the sample shape was presented tactually while the test shapes were presented visually.
The striking results to have emerged from this intriguing study were that the participants (who were tested within 48hrs of surgery on their first eye) recognized the sample shape with a very high degree of accuracy in both the unimodal visual and unimodal tactile/haptic conditions (98% and 92% correct, respectively). However, the five participants performed at close to chance level in the crossmodal tactual–visual condition (58% correct). Held and his colleagues took these results to show that the answer to Molyneux's question is “likely negative” (Held et al., 2011). In a follow-up study, three of the five participants were tested again on the tactual–visual task. Performance improved dramatically (to around 80% accuracy) within five days of initial testing. These researchers summarize the implications of their research findings by suggesting that: “It is interesting to speculate on the possible ecological importance of a learned, rather than innate, mapping between vision and haptics” (Held et al., 2011, p. 552).4
Held et al. (2011) used shapes that were quite complex (see Figure 1), combining both angular/round with squared features, instead of simply contrasting a sphere and a cube, as had originally been suggested by Molyneux (Schwenkler, 2012, or a square vs. circle, as suggested by others, to eliminate problems associated with processing depth). It is easy to imagine here how the complexity of the shapes used by Held et al. might have necessitated a longer period of learning (thus preventing immediate crossmodal transfer, Schwenkler, 2012, 2013, 2019; cf. Todd, 2004). Moreover, in a similar task, Fine et al. (2003) found that a congenital cataract patient with vision restored in one eye whom they were studying was able to identify 3D shapes with perfect accuracy when the stimuli included visual cues that simulated object motion; similarly, the participants in a study by Ostrovsky et al. (2009) were better able to identify photographic images of objects that are frequently seen in motion in everyday life (see also Gregory, 2003; Huber et al., 2015; McKyton et al., 2015; Ostrovsky et al., 2006; Šikl et al., 2013). These findings therefore suggest that sensory information obtained from object motion may be key to the formation of the robust mental, or amodal, representations of shape needed to successfully perform the crossmodal transfer task.
Despite the experimental effort that has been devoted to answering the Molyneux question, the question of the relationship between the visual and tactile representations of shape has not, thus far, been satisfactorily answered empirically (nor will it ever be, at least not according to Jacomuzzi et al., 2003; cf. Degenaar, 1996). Evidence that the surgical restoration of vision provides only a limited capacity for 3D form perception in the period immediately after surgery makes it reasonable to hypothesize that Held et al.’s (2011) participants may have failed to match seen with felt shape because they were unable to form the visual representations of the shapes in the first place.5 This hypothesis could be further supported by evidence showing that the newborn’s visual system (to which one can compare the newly-sighted one of adults, e.g., Meltzoff, 1993) is characterized both by weak acuity and contrast sensitivity (Allen et al., 1996), as well as by a poor ability to fixate, and uncoordinated saccadic and other ocular movements (Ricci et al., 2008; cf. Ueda & Saiki, 2012). Berkeley (1950) put it a radical way, excluding any possible phenomenological relationship between seen and felt objects: “But if we take a close and accurate view of things, it must be acknowledged that we never see and feel one and the same object. That which is seen is one thing, and that which is felt is another […] the objects of sight and touch are two distinct things. It may perhaps require some thought to rightly conceive this distinction. And the difficulty seems not a little increased, because the combination of visible ideas hath constantly the same name as the combination of tangible ideas wherewith it is connected […].” (see also Schwenkler, 2013, 2019).6
Given the above, the Molyneux question would seemingly remain open and thus potentially benefit from being considered from a different perspective (cf. Deroy & Auvray, 2013; Piller et al., 2023).7 In what follows, we explore the possibility of reframing the Molyneux question in terms of the crossmodal matching of stimulus intensity.
2 Old and new versions of the Molyneux question
What happens if the Molyneux problem were to be considered in terms of the emerging literature on crossmodal correspondences (Spence, 2011)? Crossmodal correspondences have been defined in terms of the often-surprising, yet consensual associations between stimuli, attributes, or dimensions of experience in one sensory modality and another stimulus, attribute, or dimension of experience presented in a different sensory modality (Spence, 2011; Walker-Andrews, 1994). As Guellaȉ et al. (2019, p. 1) wondered a few years ago: “Are infants able to make cross-sensory correspondences from birth? Do certain correspondences require extensive real-world experience? Some studies have shown that newborns are able to match stimuli perceived in different sense modalities. Yet, the origins and mechanisms underlying these abilities are unclear.”
Importantly, certain researchers have argued that crossmodal matching is possible only following some degree of infant development to establish the relevant neural mechanisms (Ettlinger, 1967). Note here also the much older argument in the developmental literature between those researchers, like Jean Piaget (1937), who assumed that the newborn’s experience of the world begins with separate senses, and Eleanor Gibson (1969) who considered it plausible that the newborn might be capable of unified multisensory perceptual experiences from the get-go. As Meltzoff and Borton (1979, p. 403) put it, one hypothesis “is that the detection of shape invariants across different modalities is a fundamental characteristic of man's perceptual-cognitive system, available without the need for learned correlation.” [emphasis added].
One way to think about the Molyneux question in terms of crossmodal correspondences might be to ask whether an individual born blind, on regaining their sight, would spontaneously match stimulus intensity (i.e., how salient the perceptual experience is) across the senses. This suggestion is based on S. S. Stevens’ (1957, 1971) early intuition that there may be a structural correspondence based on increasing stimulus intensity, possibly represented by increased neural firing in all of the senses. Given the suggestion that such a mapping results from the hard-wired pattern of neural coding (though it should be noted that no empirical evidence has yet been put forward in support of this particular intriguing suggestion), it might be imagined that intensity-based crossmodal correspondences would not have to rely on perceptual experience in order to be established. Studies of crossmodal intensity matching in adults have been reported by a number of psychophysicists (e.g., Root & Ross, 1965; Stevens & Marks, 1965). However, a detailed discussion of whether what is being matched is a relation between two stimuli or an absolute magnitude of a single stimulus falls beyond the scope of the present article (see Mellers & Birnbaum, 1982; Stevens & Marks, 1980).
Relevant here, Lewkowicz and Turkewitz (1980) suggested more than four decades ago that the crossmodal equivalence of auditory loudness and visual brightness is present in babies within the first month of life (see Section Crossmodal shape matching in human neonates for a full explanation of this study). If true, this would contrast with a number of other crossmodal correspondences that are putatively based on the internalization of the statistics of the environment, and which presumably emerge only after sufficient relevant perceptual experience (Deroy & Auvray, 2013), and/or development of the relevant concepts (see Marks et al., 1987). However, our own intuition is that the matching of stimulus intensity across the senses (say auditory loudness and visual brightness) will likely also only emerge gradually after the restoration of sight (e.g., in congenital cataract patients).8
The existence of crossmodal associations (or correspondences) mediated by stimulus intensity has often been considered as proving the existence of some sort of perceptual similarity across the senses. As Marks et al. (1986) noted almost 40 years ago: “The commonality that underlies the perception of intensity seems to emanate from phenomenological, which is perhaps to say from neurophysiological, considerations. It is our view that brightness, loudness, touch, smell, and taste intensity resemble one another because all are mediated by a common mode of neural processing (e.g., greater stimulus intensities act to increase the rate of firing in a given nerve fiber or to recruit greater and greater numbers of nerve fibers). The ultimate source of the cross-modal similarity resides not in the external world but inside the skin.”9 However, Marks et al. (1986, p. 517) go on to observe that: “Loudness does not resemble sound pressure any more than pitch resembles sound frequency. But intensity has an interesting feature. Unlike other perceptions of secondary qualities such as pitch, odor quality and color (though like perceptions of primary qualities such as duration and size), intensity is common to various modalities. This cross-modal commonality has, it appears, little or nothing to do with common stimulus events. Objects may be large to both sight and touch because the objects themselves really are large (primary quality). But brightly illuminated objects need not emit loud sounds.”10 (Italics in original.) In other words, crossmodal perceptual similarity, if it exists, is suggested to originate from within the perceiver, rather than being a property of the environment (that can be internalized as a result of the relevant associative learning).
The point to note here is that discussion of innate/amodal perceptual qualities/dimensions is somehow intimately tied-up with people’s intuitions, assumptions, and/or beliefs about the possibility (or very existence) of the phenomenon of crossmodal perceptual similarity (see Di Stefano & Spence, 2023, for a review). One might wonder whether these questions can be separated, namely, if similarity across (or between) the senses can be explained without the need to assume the existence of some sort of amodal, or intersensory, quality. Philosophers and psychologists have long agreed that similarity is a key organizational principle underlying perceptual experience and grounds the ability of humans to categorize objects into different classes (see Plato’s Parmenides, as discussed by Allen 1997; and Ryle 1939a, 1939b; see also Gentner and Medina, 1998; Goldstone and Barsalou, 1998; Goldstone and Son, 2012; Goodman, 1972; Quine, 2000; Segundo-Ortin and Hutto, 2021; Tversky, 1977). In turn, this ability is related to the formation of mental categories, or concepts, which group many different things based on some shared feature (Plato, Republic, 596a, see Reeve, 2004). If two stimuli presented to different senses cannot be conceived of in terms of mere identity, some degree of similarity needs to be admitted when it comes to accounting for consensual matchings across the senses.11
As Marks (1989, p. 58) has written: “In a cross-modality matching task, for example, virtually all subjects will set higher sound frequencies to match greater visual intensities (Marks, 1974, 1978), thereby revealing a universal appreciation of similarity between the dimension of pitch on the one hand and that of brightness on the other.” But why should we admit to the possibility of crossmodal perceptual similarity, given both recent and historic arguments against the very possibility of making such judgments crossmodally (see Di Stefano & Spence, 2023; Helmholtz, 1878). At the same time, one might wonder whether a sensitivity to polar correspondences (e.g., Proctor & Cho, 2006; see also Smith & Sera, 1992) might not provide sufficient grounding for such crossmodal matching without the need to introduce the concept of perceptual similarity.
An additional point to note here concerns the fact that information concerning (increased) neural firing is not directly accessible to the perceiver. Thus, one needs to assume that it is rather the phenomenological, and thus perceivable, effect of the neurophysiological variations that grounds the possibility of establishing similarity across the senses (e.g., the intensity of visual brightness and auditory loudness). However, should this be the case, it would remain unclear what exactly mediates the similarity observed at the phenomenological level, given that sensory information regarding intensity across the senses manifests itself in a phenomenologically incommensurable/dissimilar way (e.g., the increase of brightness is not similar to the increase of loudness in any intuitive way), as highlighted by Marks and colleagues in the above quote.
3 Crossmodal matching: Empirical evidence
Having set the scene, we now wish to review the empirical evidence concerning the early (developmental) emergence of the crossmodal matching of shape, intensity, and beyond. While it is becoming increasingly clear that human neonates/infants become sensitive to different crossmodal correspondences at different stages of (early) development (Marks et al., 1987; Meng et al., 2023; Speed et al., 2021; see Spence, 2022, for a review), there would appear to be little convincing evidence for the existence of any innate sensitivity to amodal perceptual qualities/dimensions, contrary to the claims/assumptions of at least some developmental researchers.
3.1 Crossmodal shape matching in human neonates
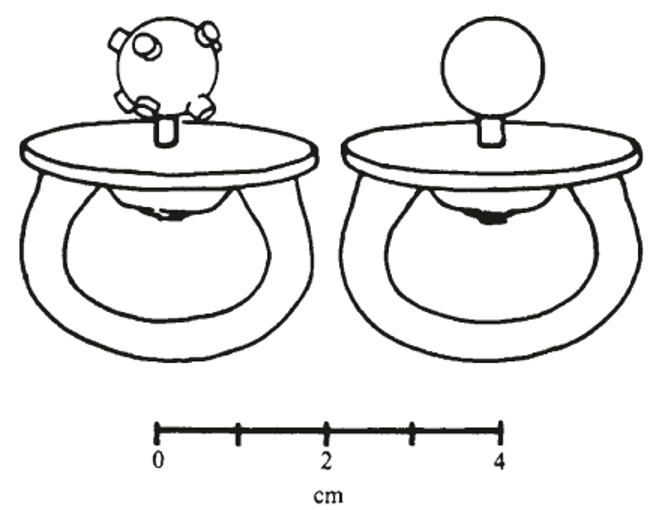
In a now-classic developmental study, Meltzoff and Borton (1979) had 32 infants aged from 26-33 days old, engage with one of two pacifiers (one smooth and the other nobbled; see Figure 2) for 90 seconds (before removing it) and then presenting the infant with both pacifiers visually. Crucially, the infants demonstrated a significant preference (in terms of their visual fixation) for the pacifier that had been explored orally (attracting 71.8% of fixation time, as compared to a chance level of 50%). This phenomenon was described as indicating some kind of tactual-visual correspondence. This finding was replicated in a second study with the same number of infants (attracting 67.1% of fixation time). However, even were these results to have proved replicable, which unfortunately they have not, one might wonder whether what is actually transferred12 might not be stimulus hardness (rather than shape, Gibson & Walker, 1984), texture (see Picard, 2007; Sann & Streri, 2007; Streri & Hevia, 2023; cf. Molina & Jouen, 2003), or even numerosity (i.e., of the nubs, Farzin et al., 2009; Izard et al., 2009). Also left unanswered is the question of the orientation-specificity of such crossmodal matching effects (see Huber et al., 2015; Lacey et al., 2009; Ueda & Saiki, 2007), and whether the size of the stimuli matters or merely their shape: Imagine for a moment the infants being shown a pacifier of the same size but different shape versus of different size but the same shape features.13 Which would win out in terms of capturing the infant’s visual attention? There is currently no evidence on which to answer this important question (see also Chen et al., 2004, on audio-oral crossmodal matching in neonates).
When thinking about the normally-sighted, it is worth considering the way in which we typically effortlessly recognize shapes through vision and touch, and novel shapes first encountered through one modality can be re-identified through the other (Norman et al., 2004). That said, in the normally sighted, vision plays a more important role than touch in visuo-haptic object recognition (Kassuba et al., 2013; Pietrini et al., 2004). Relevant here, Cao, Kelly, Nyugen, Chow, Leonardo, Sabov, and Ciaramitaro (2024) recently studied the acquisition of audio-haptic matching in sighted and blind children, and pointed to the inefficient haptic exploratory strategies seen in blind children. Simplifying our discussion from the perception of shape to the perception of length, it has also been suggested that there may be differences among varieties of perceived length. Indeed, the non-commensurability of measures of length as presented in different sensory modalities have long discussed (e.g., Jastrow, 1886; Teghtsoonian & Teghtsoonian, 1970; Waterman, 1917).
It is, though, important to stress that Meltzoff and colleagues’ (Meltzoff, 1993; Meltzoff & Borton, 1979) infant oral-tactile habituation studies have proved surprisingly difficult to replicate (Maurer et al., 1999; though see also Streri & Gentaz, 2004). For instance, Maurer and her colleagues reported on a series of three studies in which they tested 1-month-olds on their crossmodal matching abilities using exactly the same experimental procedure as described by Meltzoff and Borton. Crucially, however, Maurer et al. also included controls for stimulus preference and side bias (referring to any tendency for neonates to preferentially orient to one side versus the other). In their first experiment (N = 48), infants' looking times to smooth and nubby visual stimuli were not influenced by oral exposure to one of the shapes during the preceding 90 s, except for an effect on the first test trial in one group of participants. However, this result was put down to limited crossmodal transfer, to a Type 1 error, or to side bias, possibly interacting with a small stimulus preference. Furthermore, this effect was not replicated in a new group of 16 infants who exhibited less bias (Experiment 2), thus suggesting that it did not reflect a genuine crossmodal transfer of structural or shape information. Finally, Maurer et al. conducted a third experiment (N = 32), that was an exact replication of Meltzoff and Borton's original study. Once again, though, the results failed to yield any evidence of the crossmodal matching of shape information between oral-touch and vision.
Meanwhile, Streri and Gentaz (2003) conducted a similar study using manual instead of oral exploration. In a haptic familiarization phase, newborns were given an object to explore manually without seeing it; then, in a visual test phase, they were shown the familiar object paired with a novel one for 60 seconds. The participants consisted of 24 newborns (mean age: 62 hours). An experimental group (12 newborns) received the two phases successively (haptic then visual) while a baseline group (12 newborns) received only the visual test phase with the same objects as the experimental group but without the haptic familiarization phase. The results revealed that the newborns in the experimental group looked at the novel object for longer than the familiar one.14 In contrast, the newborns in the baseline group looked equally at the two objects, thus showing that newborns can transfer shape information from touch to vision before they have had the opportunity to learn the pairing of visual and tactile experiences. Should such results prove replicable, then it might be taken to suggest that manual tactile to visual crossmodal transfer develops prior to oral-visual shape transfer.
A number of other researchers have obtained rather mixed evidence for crossmodal shape transfer in older infants (e.g., Rose et al., 1981; Streri, 1987; Streri & Pecheux, 1986). For example, Rose et al. assessed crossmodal shape transfer between oral or tactile and visual exploration of the same stimuli in 6-month-old infants. However, across a series of three studies (N = 25-30 infants in each study), these researchers obtained no evidence that was deemed consistent with the existence of oral-visual transfer (as had been reported by Meltzoff & Borton, 1979), while tactile/haptic-visual crossmodal transfer was only demonstrated under those conditions where the necessity to retain stimuli in memory was eliminated, i.e., by allowing oral/tactile exposure at the same time as the visual stimuli were presented. However, while this step undoubtedly eliminates the requirement to hold the shape of a stimulus in some kind of memory store, the fact that crossmodal transfer occurred between stimuli that were presented simultaneously from different spatial locations is presumably foregrounded in a way that is simply not the case when the unimodal exposure to the stimuli occurs sequentially. A fourth study (N = 20) provided some borderline-significant evidence for intramodal visual transfer in 6-month-olds. In summary, therefore, no evidence of oral-visual transfer in 6-month-olds, only tactile-visual transfer when a suitably long familiarization period (60 seconds long not 30 seconds) and when two unimodal stimuli are presented simultaneously (to eliminate memory). All-in-all, crossmodal shape transfer was less robust than amongst the older infants. Such a pattern of results also question the robustness of Streri and Gentaz’s (2003) findings in much younger infants.
Taken together, therefore, the evidence that has been published over the last half century or so would not appear to provide any particularly convincing support for the claim that neonates (more specifically, one-month-olds) can crossmodally match visual and oral-tactile shape properties (see also Brown & Gottfried, 1986; and Pêcheux et al., 1988, for additional failures to show robust crossmodal transfer of shape information in infants). Indeed, one might anyway question just how developed an infant’s oral stereognosis abilities and/or their information processing capacities actually are at just one-month of age (Jacobs et al., 1998; see also Bushnell, 1994; Waterman, 1917), not to mention questioning the status of their working memory abilities (cf. Rose et al., 1981), and the extent to which memory systems are shared across the senses at that (st)age (cf. Goodnow, 1971). The latter would presumably be required, given that the pacifier was removed prior to their visual presentation (see Bremner & Spence, 2008; Ernst, 2007).15 Bear in mind here also the fact that the orally-palpated and seen objects were not presented from the same spatial location either (Filippetti et al., 2015; cf. Lawson, 1980). Indeed, perhaps before the coordination between vision and grasping is well-established, it might be expected that the intermodal transfer between touch and vision would be hard to establish (Streri & Hevia, 2023).
3.2 Crossmodal shape transfer in other species
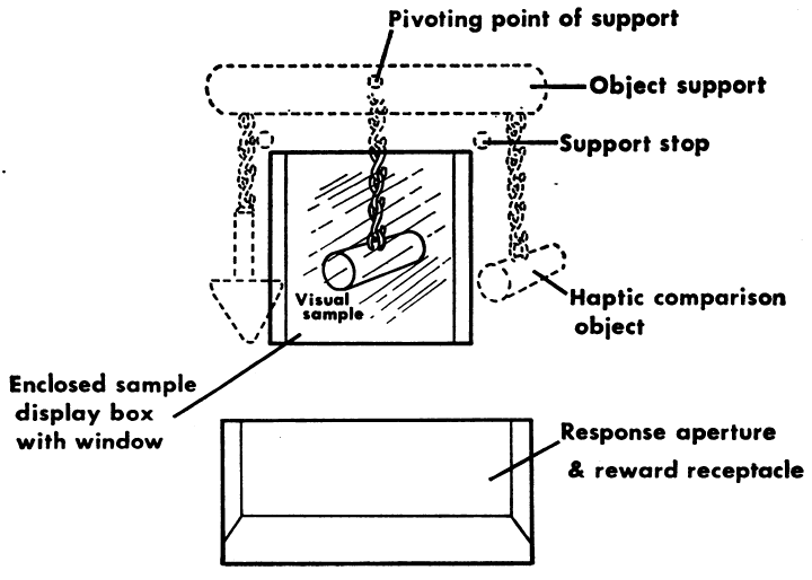
Shifting now to the crossmodal transfer of shape information in other species (e.g., Cowey & Weiskrantz, 1975; Davenport & Rogers, 1970). Davenport and Rogers studied crossmodal shape matching in a group of chimpanzees and orang-utans (N = 5). In particular, these researchers demonstrated that intermodal equivalence (or rather, intermodal transfer, that is, the ability to match one of two felt shapes with the matching visual object) could be acquired in apes (three chimpanzees and two orang-utans) (see Figure 3). One does, though, of course, need to be cognizant of the fact that extensive training is needed when working with animal participants to bring them up to the level of even human infants. What is more, the fact that the animals could see the two objects while simultaneously feeling the hidden tactile object once again presumably eliminates the need for the animals to rely on memory to perform the crossmodal matching task. Nevertheless, the results do highlight what appears to be an impressive ability to engage in crossmodal transfer of shape from touch/haptics to vision. That said, the simple fact is that the appropriate answer in this task is to match the tactile/haptic and visual impressions that happen to relate to the same object. One might wonder how performance would change is the apes were tasked with learning an arbitrary mapping between unrelated felt and seen shapes (i.e., mere contingency learning versus picking up on some common external shape property). By using edible and inedible shapes, presented first to rhesus monkeys in darkness, then in the light, Cowey and Weiskrantz (1975) were able to demonstrate cross-modal matching from touch to vision. As such, crossmodal matching should not be considered as unique to apes and humans (see also Zhou & Fuster, 2000).
3.3 Crossmodal intensity matching in human neonates
Lewkowicz and Turkewitz (1980) conducted a seminal study in which they investigated the crossmodal matching of audiovisual stimulus intensity in a group of 3-week-old infants. The infants were repeatedly presented with white-light followed by white-noise stimuli at different intensities. A U-shaped relationship between the magnitude of the infant’s cardiac response (CR) and the loudness of the sound was observed. In view of previous findings that without prior visual stimulation a monotonic increase in CR to the same range of auditory stimuli results, this finding of a significant quadratic relationship with loudness was taken to suggest that infants were responding to the auditory stimuli in terms of their similarity16 to the previously-presented visual stimulus.17 However, rereading this frequently-cited paper, it is noticeable how the authors initially assume intensity to be an amodal dimension (in that it is a quality that can be perceived in different modalities),18 but then go on to describe their findings merely as showing that quantitative differences (e.g., in stimulus intensity) may be more salient than qualitative differences (e.g., in modality) in stimulation early in human development, either as a result of a lack of sensory differentiation, or else as a result of selective attention being captured more by intensity changes. Intriguingly, however, the results of a study with 31 adults did not show any systematic relationship between CR and loudness, indicating that unlike infants, adults do not appear to make such crossmodal intensity matches spontaneously.19
One of the challenges when it comes to evaluating the putatively innate nature of crossmodal intensity matching comes from the confusing definitions of visual stimuli intensity used by at least certain influential developmental researchers. Take, for example, Bahrick et al. (2004, p. 99) who at one point state that: “One type of overlap involves amodal information, that is, information that is not specific to a single sense modality, but is completely redundant across more than one sense.” So far, so good. However, it soon becomes unclear what exactly they mean to refer to when talking about visual intensity – certainly not the increased visual brightness, as might legitimately be assumed, and as discussed/studied by Stevens and others (Lewkowicz & Turkewitz, 1980). Just take the following quote from a review article that appeared in Current Directions in Psychological Science: “The sights and sounds of a ball bouncing are synchronous, originate in the same location, and share a common rate, rhythm, and intensity pattern. Picking up this redundant, amodal information is fundamental to perceptual development […] the face and voice of a person speaking share temporal synchrony, rhythm, tempo, and changing intensity” (Bahrick et al., 2004, p. 99). It is entirely unclear (at least to the authors of this review) what visual intensity is meant to refer to in this case.
3.4 Development trends in crossmodal correspondences
Although there has been some disagreement, developmental researchers would now appear to have established when during human development the sensitivity to different crossmodal correspondences typically emerges (e.g., Marks et al., 1987; Spence, 2022; Streri & Hevia, 2023; Walker et al., 2010, 2014).20 Indeed, according to one hypothesis, the early integration hypothesis, cross-sensory integration is already present from birth onwards, while according to another hypothesis, the late integration hypothesis, the role of experience in the development of cross-sensory associations is emphasized (Dionne-Dostie et al., 2015; cf. Schwenkler, 2012).21 The stage in human development at which a sensitivity to various different (kinds of) crossmodal correspondence can be demonstrated is currently a particularly active area of empirical research. Looking to the future, it would also be of interest to determine whether different classes of crossmodal correspondence are represented differently in the brain (Guellaȉ et al., 2019, p. 5). Indeed, it would seem eminently plausible to assume that different classes of correspondence might well emerge at different stages during the course of human development.
4 Conclusions
In conclusion, in the present review, it has been argued that the continued interest in the ‘Molyneux problem’ can be seen as resulting from the intuitive, though we would argue misguided, notion that shape information is coded amodally, at least by the senses of vision and active touch (i.e., haptics). At the same time, however, neither the developmental research, nor the latest findings from congenital cataract patients’, whose sight has been restored (Held et al., 2011), would appear to provide any convincing evidence that such crossmodal matching can be achieved in the absence of the relevant sensory experience (i.e., as a result of associative learning/repetitive exposure). Similarly, there is surprisingly little evidence to support the notion that the matching of stimulus intensity across the senses is either innate or amodal either though it may be acquired early in life. However, as we have seen, the evidence on which such a claim is based (Lewkowicz & Turkewitz, 1980), is open to multiple interpretations, and has also yet to be replicated. Nor, we would argue, is there any reason to suspect that audiovisual stimulus intensity necessarily reflects a Gibsonian affordance that needs no integration (Gibson, 1977).22
Furthermore, considering the distinct nature of sensory impressions and how they are processed by the two sensory systems, it remains unclear how exactly haptic input could be effectively translated into a visual format (or vice versa) to generate an amodal representation of shape (or intensity). As such, the notion that shape (and intensity) are somehow special perceptual qualities/dimensions (i.e., amodal and/or innate, see Lewkowicz & Minar, 2014; Maurer et al., 1999) should presumably be abandoned. In its place, it can be argued that it makes more sense simply to accept that different classes of crossmodal correspondence are acquired at different times/rates during the course of human development.23 We believe that figuring out the relevant constraints on the acquisition of different classes of crossmodal correspondence, which are based on similar neural coding, similar phenomenology, similar hedonic associations, and/or shared lexical descriptors would appear to constitute a more promising approach to furthering our understanding in this area than continuing to pursue an empirical answer to the original Molyneux question which, as has been argued by others, might be best left as a historical thought experiment. To be absolutely clear, the suggestion that is put forward here is that while a prolonged focus on the visual-haptic shape correspondence version of the Molyneux question may have hindered research and theoretical progress in thinking about the origins of crossmodal matching, there are various other versions of the crossmodal matching question that deserve further empirical and theoretical scrutiny.
Crucially, the latter approach is less theoretically laden with regards to the existence of amodal perceptual qualities and assumptions concerning the innate nature of certain perceptual abilities (as promoted, for example, by the work of J. J. Gibson, see Spence & Di Stefano, 2024). Moreover, it avoids framing the Molynuex’s question, as well as many other issues that arise from developmental perception research, from the innatist vs empiricist debate, which would appear to misconceive the nature of biological universals and how they manifest in individuals. Alternatively, we suggest that dichotomies such as innate/learned may be more effectively reconceptualized in a continuous fashion, namely, in terms of the ease and success of the process of acquiring skills rooted in biology as opposed to those that are more imbued by culture. For instance, learning to walk or speak may be more readily, easily, and effectively achievable targets for most people compared to mastering purely cultural skills such as playing the violin or drawing.
Extending the Molyneux problem to the chemical senses could also prove to be a fascinating avenue of investigation. Research in this area could, for example, involve experiments in which the participants are initially exposed to certain spices or ingredients through taste only and then later presented with visual stimuli related to those tastes to assess their ability to make accurate visual identifications (cf. Ngo et al., 2013). Such investigations could presumably contribute to our understanding of crossmodal perception and the integration of sensory information in the human brain.
Acknowledgements
The authors wish to acknowledge the very helpful suggestions made by two anonymous reviewers to earlier versions of this manuscript.
References
With some thinkers even changing their mind, such as Condillac, who first gave a positive answer and then opted for a negative one, years later (Anstey, 2023).↩︎
“Ideas which are said to come from more than one sense—such as those of space, figure, motion, rest—come rather from the common sense, that is, from the mind itself” (Leibniz, 1981, p. 135).↩︎
One other question to consider here is whether the congenitally blind are capable of acquiring an understanding of geometry? Marlair et al. (2021) created 3D-printed tactile shapes to investigate the intuitive understanding of basic geometric concepts in blind children and adults. The participants were exposed to four shapes at a time, three instantiating a particular geometric concept (e.g., line vs. curve, parallel vs. secant lines, symmetry) while the remaining one violated it. The participants had to examine all of the shapes in order to detect the one that one differed most from the others. The results showed that both the blindfolded sighted and congenitally blind individuals were able to perform this task at above chance levels, thus suggesting that basic geometrical knowledge can develop in the absence of visual experience. However, that said, it should be noted that the blind were significantly worse on this task than the sighted participants performing the same task in the visual modality (i.e., with their eyes open). However, they performed just as well as the sighted performing the task in the tactile modality (i.e., while wearing a blindfold), thus suggesting that the lack of vision somehow impacts on the understanding of geometrical concepts.↩︎
Held here would appear to equate a yes/no answer to the Molyneux question with the distinction between innate and learned. However, this may be too hasty. Relevant here, Locke points to the fact that people assent to certain propositions upon first hearing them does not prove that those propositions are innately stored in them; it may happen just because those propositions are obvious, or self-evident (Essay, I.ii.17-18). Similarly, suppose it were a fact that many newly-sighted individuals were to immediately recognize a circle seen for the first time as the object they previously knew as a circle by touch. That might happen just because there is a manifest similarity between seen circles and felt circles, not because there is an innate connection between the visual and haptic representations of circularity. (See Evans (1985) for the point that similarity and innateness are competing explanations of yes to Molyneux.) At the same time, however, it should be noted that the concept of “manifest similarity” might itself be problematic. One should at least admit that the subject must possess the ability to detect such similarity between seen and felt circles before their initial exposure to these stimuli, as in the case of the Molyneaux question. Moreover, while similarity might be straightforwardly applied to stimuli presented within the same sensory domain, it is far less intuitive to talk about similarity across the senses (see Di Stefano & Spence, 2023, for a review).↩︎
That said, an explanation is still needed for how these individuals performed near-perfectly in the intramodal visual matching task.↩︎
The radical import of Berkeley’s words should not be forgotten. If the subject is given the question, “which of the things you now see before you is what you previously knew by touch as a sphere,” Berkeley would have to say that the correct answer is neither. For nothing seen was ever previously touched; visible objects and tangible objects do not even inhabit a common space.↩︎
Here, it is interesting to note that the incredibly robust ‘Bouba-Kiki effect’, namely the sound symbolic matching of round and angular shapes seems not to occur in the congenitally blind (Sourav et al., 2019), nor immediately in congenital cataract patients once their sight has been restored. Rather, much like the cross modal shape matching reported by Held et al. (2011), appears gradually following the restoration of sight (Piller et al., 2023).↩︎
Moving to the chemical senses: One could have sighted participants taste an unfamiliar fruit (under blindfolded conditions) and then have them identify which of two foods they had tasted. The evidence suggests that sighted participants are able to infer at better than chance levels whether a given fruit juice came from a large or small fruit (see Ngo et al., 2013).↩︎
Elsewhere, note, we have taken issue with the idea that there is any kind of perceptual similarity across the senses (Di Stefano & Spence, 2023).↩︎
One might choose to take issue with the claim that objects may be ‘large’ to both sight and touch “because the objects themselves really are large”. Almost by definition, we are unable to feel large objects, like planets or skyscrapers, only inspect them visually.↩︎
An example from Evans (1985, p. 372) in which the manifest similarity of a feature presented in one sensory modality and a feature presented in another sensory modality should make us expect successful matching: ‘Continuous’ and ‘pulsating’ (or ‘intermittent’) are learned by a deaf person through skin stimulations; upon gaining hearing, s/he is then presented with continuous and intermittent tones. Evans’ position is that few of us would have a doubt about whether s/he should be able to recognize which is which. (One could reimagine this as involving touch and vision; a broomstick and a row of pebbles of the same diameter as the stick are presented first to touch and then to vision.)↩︎
Note that crossmodal transfer, as opposed to crossmodal integration, has been identified as especially important by a number of researchers (e.g., Guellaȉ et al., 2019).↩︎
See Cowey and Weiskrantz (1975) for a crossmodal matching study in rhesus monkeys where precisely such a comparison caused problems – in particular, mostly regardless of whether the monkeys had been presented with a small or large edible disc (and a large or small inedible disc) in darkness, they chose a larger disc when presented with them visually.↩︎
Note that this is the opposite pattern of behaviour to that reported by Meltzoff and Borton (1979). Inconsistencies might be related to a behavioural paradigm that is based on a single measurement (i.e., looking time), as highlighted by Trehub (2012).↩︎
Relevant to this point, newborns can learn arbitrary auditory-visual associations (such as between an oriented coloured line and a syllable), but only when the visual and auditory information are presented synchronously (Slater & Kirby, 1998). At the same time, according to Slater and Kirby, newborns can associate objects and sounds on the basis of temporal synchrony.↩︎
One might here want to question how ‘similarity’ is operationally defined in the experimental protocol.↩︎
That said, there is obviously much inference required to reach this intriguing conclusion. And, as highlighted elsewhere in the context of claims regarding the putative existence of neonatal synaesthesia, it is difficult to know whether a neonate perceives stimuli presented in different modalities as being similar, versus simply failing to distinguish perceptually between them (see Deroy & Spence, 2013).↩︎
They write that: “Amodal features are those that can be used to identify an aspect of an object or an event in more than one modality, whereas modality-specific features can only be used to identify an aspect of a stimulus that is peculiar to a single modality. Thus, intensity, rate, duration, spatial location, spatial extent, rhythm, and shape all represent amodal features of the world that can be specified in more than one modality. They stand in distinction to such modality specific features of stimulation as redness, sweetness, and pitch.” (Lewkowicz & Turkewitz, 1980, p. 597).↩︎
Intriguingly, there would appear to have been no attempts to replicate this seminal study, despite it having been published only one year after Meltzoff and Borton’s (1979) study. The closest may be a conference paper read by Wilson (1969) in which it was apparently reported that animals do not transfer responses to stimulus intensity change from one sensory modality to another, thus seemingly contrasting with Lewkowicz and Turkewitz’s (1980) findings.↩︎
As Lewkowicz and Turkewitz (1980, p. 606) note in their early study: “Our approach further suggests the caveat that care be taken to distinguish between various types of cross-modal equivalence. That is, some equivalences may be based on primitive and undifferentiated functioning, whereas others may represent the highest levels of cross-modal functioning and may involve perceptual and cognitive as well as sensory mechanisms.”↩︎
Guellaȉ et al. (2019, p. 5) ask whether there: “Are general associative learning mechanisms sufficient to explain how infants come to pair sensory cues across modalities, or do specific learning processes or constraints guide the acquisition of some (or all) cross-sensory correspondences?”↩︎
According to Gibson’s (1979) ecological theory of perception, amodal information (or information that is not specific to any one modality and that can be conveyed redundantly across several senses), is obtained directly from adaptive interaction between organisms and their environments. It should though be noted that Gibson only proposed that amodal spatial and temporal dimensions were available to all sensory modalities from birth.↩︎
It should also be noted that sound symbolism does not appear to be present within the first month of life (Ozturk et al., 2013; Sidhu et al., 2023).↩︎