

1 Introduction
William Molyneux sent John Locke a letter in 1688 posing a question about the relation between sight and touch (as others have noted, it may have been inspired by a work of Ibn Ṭufayl that had recently been translated into Latin and which had posed a distinct but similar question).1 Locke did not respond to this first version, but several years later Molyneux tried again, and this version of the question interested Locke and he included discussion of it in the second edition of his Essay. The question was the following:
Suppose a Man born blind, and now adult, and taught by his touch to distinguish between a Cube, and a Sphere of the same metal, and nighly of the same bigness, so as to tell, when he felt one and t’other; which is the Cube, which the Sphere. Suppose then the Cube and Sphere placed on a Table, and the Blind Man to be made to see. Quaere, Whether by his sight, before he touch’d them, he could now distinguish, and tell, which is the Globe, which the Cube.
This version of Molyneux’s Question (MQ) has played an important role in the history of philosophy and psychology.2 It puts forward in a vivid and seemingly straightforward example the many difficulties that arise when we think about the relation between sensory modalities, and about the methods and theoretical foundations used to settled debates about certain classes of experiences. This question has had a remarkable run, and its continuing interest (as evidenced by this very special issue, among others) would suggest that it’s settled that Molyneux’s Question remains an important tool in philosophy and cognitive science.
In this paper I reject this assumption. I will argue that—while the question itself has had immense importance across several domains for more than three centuries—it is not a question that, by itself, will settle any outstanding theoretical or methodological challenges. As I see it, the contemporary near consensus across a range of domains undercuts the theoretical and practical important of Molyneux’s Question. In other words, I will argue that we should have no expectation that there will be any theoretically interesting answers to MQ, and that the question itself no longer serves to motivate any interesting empirical findings in the area.3 This is not to say that the question cannot be an important intellectual tool for thinking and engaging with the underlying issues; the claim defended here is only that no particular experiment will settle it or provide any independent evidence that could be used to settle a foundational dispute.
The argument for this view is grounded in two thoughts: First, MQ is generally under-specified, and can be made precise in multiple incompatible ways. There are thus many different formulations of the question, and these different formulations build in different assumptions and purposes that will likely lead to very different answers to the question. This first point has already been well noted by others in the recent literature (especially Matthen & Cohen, 2020). The second point has not, to my knowledge, received similar discussion: even if we restrict ourselves to a more specific version of MQ, we should still expect there to be several reasonable but incompatible answers to the question. This will occur because of variability in the theoretical choices available prior to and downstream from the formulation of the question itself. For instance, before we can answer any precise formulation of MQ, we must make decisions about how we individuate touch from vision, and about how we individuate these from the many non-perceptual elements that interact and integrate with them. The current consensus is that this is no easy task. There are thus multiple plausible ways of drawing the various distinctions that would generate different responses to any particular formulation of MQ. It’s not just the individuation conditions of the senses that generates the worry, either. More fundamentally, the issue arises even for how we think about sensory representations and psychological explanation in general. Our best contemporary accounts here are often inherently pluralistic, non-essentialist, modestly interest-relative, and multivariate, and so we should reasonably expect there to be several possible ways of answering even the more precise formulations of MQ (Craver, 2009; Shea, 2018). What follows from this is that we should not expect any answer to MQ to settle debates about the nature of sensory content, multisensory interaction, or mechanistic explanation about the senses, since how we answer any particular MQ will depend at least on how we individuate the senses involved, the kinds of content we believe are available in each modality, and on our preferred taxonomy for sensory interaction.
The focus of this paper will be an elaboration and defense of this second line of thought. I will begin with a short discussion of the first worry—that MQ admits of several distinct formulations that could support different answers—before moving on to the main focus of the paper, which is a defense of the second claim: even if we can nail down a specific version of MQ, the answers we get will depend on a host of other interconnected theoretical commitments.
2 Many questions: The under-specification worry
As mentioned above, Molyneux actually sent Locke two versions of his question. The original version from 1688 read:
A Man, being born blind, and having a Globe and a Cube, nigh of the same bignes, Committed into his Hands, and being taught or Told, which is Called the Globe, and which the Cube, so as easily to distinguish them by his Touch or Feeling; Then both being taken from Him, and Laid on a Table, Let us Suppose his Sight Restored to Him; Whether he Could, by his Sight, and before he touch them, know which is the Globe and which the Cube? Or Whether he Could know by his Sight, before he stretch’d out his Hand, whether he Could not Reach them, tho they were Removed 20 or 1000 feet from Him?
This version doesn’t simply ask about whether a subject could “distinguish” and “tell” one shape from another using vision alone. Instead, it is framed in terms of knowledge, and includes mention of distance as well as shape.4 Thus we can see even in its earliest formulations, there were multiple versions of the question that focused on distinct elements of the case. There are questions about what it means to “tell” or “distinguish” one shape from another, whether that amounts to the same thing as “knowing” the difference between the shapes, and then whether our answers to these questions about shape carry over to distance. One version focuses on “vision alone” while the other references “without reaching” as one of the important constraints. All of these differences are important and could produce different answers depending on how the question is made precise.
This feature of the debate has been well-noted by others. For instance, Robert (Hopkins, 2005) begins his paper on MQ by noting that “[I]t is far from obvious what Molyneux’s question is really about.” (441) He goes on to suggest at least two principal formulations of the question, one asking whether there is a property represented by both vision and touch, and another that asks, if the previous question is answered affirmatively, does it follow that tactual and visual experience have distinct concepts of that property? We can see immediately that these particular formulations are more narrowly focused than the originals and raise more specific questions whose answers will depend in part on (for instance) what we take sensory concepts to be and how we individuate sensory properties.
More recently, Gabriele Ferretti (2018) notes that there are multiple formulations of Molyneux’s Question that he takes to form two main versions: one focused on recognition and another focused on vision-for-action. The former focuses on the discriminative abilities of the newly sighted subject, and the latter focused on whether the subject could use that information to successfully perform a motor action based on that awareness. As Ferretti notes, “Now, from the fact that Molyneux subject can answer the question about which is the geometrical figure she/he is faced with (a process that is mostly, but not totally, due to the possibility of relying on ventral visual processing), it does not follow that she/he has developed the proper visuomotor skills for motor interactions.” (Ferretti, 2018, p. 647, in-line citations suppressed) And this is not the only variable element in the question. He notes an important distinction between ocular and cortical blindness that must be accounted for when attempting to provide an answer to these questions. He also notes that the popular two-visual streams model (TVSM) suggests there are two functionally-distinct forms of visual processing, one primarily descriptive and conscious, and another focused on action guidance and largely unconscious. Given these additional complexities, we can anticipate that subjects with different forms of blindness might respond differently to an experimental investigation, and that what we consider vision alone will depend on which element of vision we are probing. Ultimately, given these additional complications, Ferretti argues that the first formulation of the question cannot be empirically tested, while the second will depend on further details, providing either no answer at all or a negative one. This supports the idea that there can be distinct formulations of the original question, and moreover, that we should anticipate different answers depending on which formulation we settle on.
Brian Glenney (2013) offers a compelling formulation of this same variety. He notes that MQ seems to function like a general philosophical puzzle that admits of many more precise sub-questions, each with their own specific answers depending on how we make the general claims precise:
These selected answers, all of which focus on how the newly sighted might come to identify shapes, range over multiple levels of explanation and disciplines of study. Some focus on the neural basis of shape recognition, others the phenomenological experience of shape, or behavioral responses, mental states, the conceptual repertoire involved, not to mention the epistemological standing of the recognitional states and the metaphysical assumptions in play, each of which are explanatory features of Molyneux’s question. Not only are there various ways for the newly sighted to see and as we’ll discuss, fail to see, there are different organizational levels, such as those isolated by Marr (1982), that deserve attention (Bechtel, 1990). If Molyneux’s question is considered in its generality, then it becomes an interdisciplinary problem and many levels of explanation are of interest. (543-4)
For Glenney, these sub-questions are more precise clusters that fall under the general heading of MQ. This means that we should not expect a single univocal answer to the general question. Instead, “[T]he sub-problems that constitute Molyneux’s question are themselves in motion: the status of one part, like a subject’s level of blindness, will influence the status of others down the line, like acquisition of shape by touch. Hence, any answer to Molyneux’s question may become a rather complex account of moving sub-parts.” (544)
This interpretation of the state of play seems robust, especially given the many distinct interpretations and elaborations of MQ over the years (Campbell, 1996; Evans, 1985; Jacomuzzi et al., 2003; Morgan, 1977; Schwenkler, 2019). This concern reaches its ultimate expression and defense in a pair of recent papers by Jonathan Cohen and Mohan Matthen (Cohen & Matthen, 2020; Matthen & Cohen, 2020). Cohen and Matthen (2020) argue that MQ has many different formulations, each of which could for various empirical reasons have different answers. They offer a taxonomy of distinct versions of MQ built on distinct conceptions of spatial representation. They first break the general MQ into two categories, one dedicated to space and the other to shape, and then they characterize the more specific versions of these questions. As they note, their taxonomy “[S]uggests a new range of questions of the same type, sheds light on similarities and differences between members of the family, and allows us to formulate a much-augmented set of principles and questions concerning the intermodal transfer of spatiotemporal organization.” (52) As they conclude:
[T]here is a variety of fruitful MQs, cast in a number of spatial and temporal regimes, that are about the transferability across modalities of information about spatiotemporal common sensibles, including spatial position, shape, temporal order, and change. We have argued, pace Evans, that these cannot all be reduced to questions about the existence and character of an inter-modally shared representation of space. We have also argued that it is wrong to assume that negative answers to MQ always trace back to negative answers to zero-dimensional percepts. Consequently, these questions cannot be answered a priori or by appeal to a single principle. Different MQs have different answers, within different sets of perceptual conditions. (61)
I agree wholeheartedly with the thoughts expressed by these writers above that the original formulations of MQ are quite general and admit of multiple more precise formulations. Many of these formulations stray quite far from the original versions, and theorists have often molded the discussions around the issues and challenges most salient to their own investigative context. This malleability and flexibility can partly explain the enduring interest in MQ.
One general feature of the above approaches, however, is the thought that, while there are multiple more precise formulations of MQ, there are still likely to be interesting and illuminating answers to each of these more precise formulations. For instance, Ferretti (2018) argues that there are two distinct versions of MQ worth addressing, two forms of blindness to keep separate, and important considerations from the two-visual streams hypothesis to accommodate. But once we have clarified these points, we can settle on some specific answers:
Concerning MQ, the answer is not possible because the experimental setting imagined by Molyneux cannot be reached for empirical reasons. Concerning MQA2, the answer depends on our interpretation of the question. Either we cannot reach the experimental setting that does justice to the scenario imagined by Molyneux, as in the first case, or the answer is negative. (653)
Similarly, Matthen and Cohen (2020) note a wide range of different versions of MQ but hold that each can be given an answer: “Different MQs have different answers, within different sets of perceptual conditions.” (61)
I agree that any attempt to properly answer an MQ will require careful consideration of the formulation of the question, the kind of blindness involved, and specification of the precise content or capacity being assessed. And yet, my own view is slightly more pessimistic even than this. While I agree that there are multiple MQs, I want to resist the idea that any of the more precise versions would, on their own, provide anything like a clear answer to the kinds of foundational questions we seem to most care about. This is not an empirical point about the limits of our methods or worries about the availability of clear cases of newly acquired visual abilities. Instead, the worry is a theoretical concern that arises from recognition of where any formulation of MQ sits with respect to a host of other related issues. Even if we settle on a specific version of MQ in an appropriate explanatory context, there will still be a multiplicity of legitimate answers that arise from theoretical choices we will be forced to make that are independent of and more foundational than any of our answers to MQ.
Let’s just focus on perception and perceptual capacities here. We can think of the important questions as existing along a continuum from more fundamental to less fundamental, forming something like the classic foundationalist pyramid. At the bottom will be the most fundamental issues of basic taxonomy (What are the natural kinds if any? Which are the sensory kinds?), content (Do we accept representations? If so, which kinds? What are their semantics?), and explanation (various 4E models, various forms of computationalism, mechanistic explanation, etc). In the middle might be more specific questions, such as the imagery debate or debates about high-level visual content. At the very top we might include ongoing debates about how to interpret developmental stages using evidence from studies on neonatal looking times or sucking rates. As many critics have noted, these sorts of experiments must always be interpreted against a backdrop of more fundamental assumptions, and cannot by themselves settle debates about innateness or concept acquisition (See, e.g., Kagan, 2008; Müller, 2008).5
I submit that the more specific formulations of MQ will be in this specialized domain, always framed against a set of essential background commitments and assumptions. This is fitting, given that versions of MQ usually focuse on relatively sophisticated person-level capacities (for recognition and discrimination) that involve several distinct elements of our psychology (the senses, concepts, memories, spatial awareness, cognition, and so on) (see fig. 1).
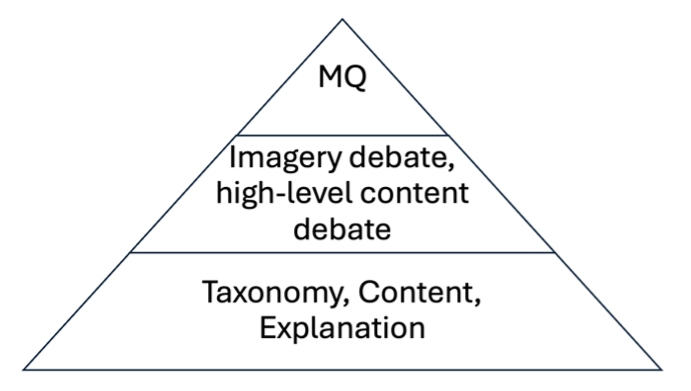
In general, the idea is that a particular formulation of an MQ will always require settling on a host of more foundational theoretical commitments (and not vice-versa). Failure to do so will always leave it possible to get conflicting answers given a change in the foundations. Our answers for any MQ, for instance, will depend in part on how we individuate the senses, our theory of sensory representation, and our preferred account of psychological explanation (to name three of the more salient considerations).
In the next section I focus on these three foundational sources of variability, each in turn. We start with the most obviously salient question of sensory individuation.
3 But wait, it gets worse!
The under-specification worry already constrains the utility of MQ. A lot of work needs to be done to make clear which version would be tested, and then of course there are all the methodological worries about getting the experiments and data collection right. I agree with this general assessment, but I think the situation is even more problematic. Even if we restrict ourselves to a specific version of MQ, and even if we manage to procure an appropriate method of empirical investigation suited to that version, the answers we get from the data will still be contingent on a host of other commitments we are required to make that are independent of the data itself. In other words, no MQ experiment by itself will independently settle a substantive debate on these other topics, because there would be a vicious circularity involved: our answers to MQ depend on our commitments in these other debates. To start: no precise formulation of MQ can be given an answer at all until we provide an account of what we mean by “touch” and “vision.” These are contested categories with many different possible points of division. Likewise, if we want to focus instead on “tangible” content or “visual” representations or activity in the “visual centers” of the brain. These categories are also contested and admit of many different plausible answers. We can’t make precise a version of MQ in a way that is neutral with respect to these choices and expect any single answer, and certainly not one that would tell us, for instance, where to draw the boundary between touch and vision.
3.1 Multisensory interaction
Pick any maximally specific formulation of MQ you want an answer to. Before you can determine the answer to this question, indeed, before you can even determine the appropriate methods, findings, or evidence that would help settle this question, you will have to make some substantive commitments about what counts as the sense of touch. This seems extremely fundamental for any version of the question about what it means to be ‘taught by touch to distinguish a cube from a sphere.’
What is touch? This is not an easy question. And not because of worries about how to understand perceptual learning and knowledge (‘taught’). Touch is surprisingly complex and it’s very difficult to clearly articulate what counts and what doesn’t count as part of touch (de Vignemont, Frederique & Massin, 2015; Fulkerson, 2015). What we usually refer to as the sense of touch is a form of haptic touch, and it’s typically active. Especially when assessing the felt shapes and sizes of external material objects. When we gently touch the coffee mug to see how large it is or lift a small box to see how heavy it is, we are engaging a very sophisticated set of capacities that use surface receptors that code for pressure, texture, slip, and thermal properties. These receptors only provide tangible awareness when coordinated with our exploratory activity. By engaging stretch receptors we can determine the dynamic properties of objects, like the length and shape of a tool wielded in the hand. Through precise movements over time, we can segment, recognize, and group complex tangible objects (Klatzky & Lederman, 2008). Our ability to determine fine shape, weight, size, and part-whole relations thus depends on several elements working together (Klatzky & Lederman, 2003). Do these other elements count as part of touch proper? Are they instead distinct elements that engage in multisensory integration? When such integration occurs over time and relies on tactual memories and imagery, do these elements count as something distinct and downstream from touch proper? The sense of touch is notoriously complex and involves interacting and seemingly distinct systems, including a wide variety of receptor types embedded in the skin which code for a number of distinct properties . No experiment alone will settle how we draw these boundaries.
Some of these elements—like those which feed into representations of peripersonal space and facial awareness, reliably interact and engage with general perceptual capacities that are also used by, or in turn influenced by, vision and visual awareness (de Vignemont, Frédérique et al., 2021; Pessoa, 2013). Recent decades of research have emphasized the many overlapping interactions that occur between senses (O’Callaghan, 2008, 2012). Our understanding of the sense of touch in particular indicates that it often engages in complex ways with the other modalities, emotional feelings and reactions, and with various general recognitional capacities (de Vignemont, Frederique & Massin, 2015; Fulkerson, 2014b; Kilgour et al., 2005).
These facts impact how we assess MQ. Does learning to recognize a cube from a sphere made of metal depend only on cutaneous surface signals, or do we allow the richer forms of awareness that make use of proprioception, kinesthesis, and motor feedback, and the general polymodal spatial representations built up by the interactions between modalities, often including vision? Importantly, there are several different means by which touch can provide spatial and shape information, and some of them are already inherently multisensory by nature (Lederman & Klatzky, 1987). If touch is already plausibly multisensory in cases of reaching and grasping, and can be so in a variety of ways (through proprioception in some cases; through vision in others), then how we answer MQ in any particular case will depend a lot on what we include as part of the touch component.
Of course, these same worries arise for vision too. Activation of receptors on the retina is one thing, but visual recognition is a complex capacity that involves immense activity downstream from there. It isn’t clear where vision ends and cognition, memory, and recognition begins (Block, 2023; and Burge, 2022 have both recently written lengthy volumes on this very issue). For instance, consider the recognition of faces through sight. There is ample evidence over many years of research that regions in the fusiform face area (FFA) are the grounds for such capacities, but these regions are both very far from the primary visual cortices and our capacity to recognize faces can be lost or degraded with no loss in primary visual function (in cases of prosopagnosia) (See, e.g., Kanwisher et al., 1997; Kanwisher & Yovel, 2006; Tsao & Livingstone, 2008). Faces thus seem like paradigm multisensory objects (Fulkerson, 2023). There debates about whether these areas subserve domain general capacities (a kind of general pattern detector) or whether they are specialized for faces (Tarr & Gauthier, 2000 defend the latter claim). This would raise some important questions about whether a capacity like recognizing cubes or spheres would require similar machinery, and about where we draw the lines between vision proper and elements downstream from vision (including memory and cognition). Settling that sort of question will depend on where we draw our lines around touch and vision and their multisensory domains. Recognition also putatively involves a kind of matching with stored representations like object files or event files (Hommel, 2004; Kahneman et al., 1992). Object files are often understood to be multisensory in nature, and to collate and collect information about objects provided by distinct modalities (and can also be influenced by cognitive engagement through expectation and other such processes). It is thus a very substantive question what we mean by “vision alone,” and whether we include the range of typical systems usually counted as part of vision itself. (Similarly, as we’ll see in the next subsection, a lot will depend on what we mean by “representations” and “concepts.”)
It is thus empirically plausible that even for researchers focused only on a more specific version of MQ, they could reasonably come to different answers depending on where they draw the lines around touch and vision, and how they theorize about the taxonomic boundaries between the senses and non-sensory elements like emotion, cognition, and motor control. This is especially true when we consider versions of the question that go beyond just shape and spatial awareness and include richer recognitional capacities that might trade on emotional or affective elements of our experiences (Pessoa & Adolphs, 2010).
To be clear, the point is not simply that there are additional details that need to be worked out in the formulation of any particular MQ, but that there is an inherent circularity in our choices across a range of issues in the individuation of the senses that will impact how we answer the question. This means that even specific versions of the question may not admit of any single answer.
3.2 Representation
Another fundamental choice point here will concern a series of independent choices we might make about the sensory representations involved in MQ cases. These elements might be the perceptual contents, the posit of object and event files, and our account of sensory and general concepts.
The idea here is that even if we hold fixed on a particular MQ, we might expect distinct answers to the question about whether we have access to the spatial representations across modalities because we might differ in how we are thinking about representations. Some might think that representations even in perception can be the result of learning. And these learned representations might involve a bit of cognition and other elements and might allow the transfer of spatial recognition across modalities. But others might have a more constrained notion of representation in mind, perhaps along the lines of teleological explanation as defended by Neander (2017) and Millikan (1984, 1989), and if this is the kind of view that someone has then they might deny that there was a transfer of representation in that sense. Finally, some might hold that representations are nothing but theoretical posits invoked to help in certain classes of explanations (Egan, 2020), and here we might imagine a much more permissive notion that could be invoked for a wider range of cases than the teleological accounts allow (and maybe even than the perceptual learning cases allow).
Let’s look in more detail at some of the options here. We could be pluralists about perceptual content. This would provide several different approaches to any particular MQ depending on which kind of content we had in mind. Jake Quilty-Dunn (2020), for instance, has argued that perception utilizes both iconic and discursive representational formats, the latter of which is a format shared with cognition (808). On the one hand, Quilty-Dunn allows that there may be proprietary iconic formats for each modality, a distinctively visual format that remains visual even when shared or deployed by other faculties (in cognition or imagination, say). On the other, he argues that perception also deploys a discursive representational format that more easily connects with cognition and eases transference across domains. He cites ample empirical evidence in favor of these views. If this view is right, then it would have clear implications for any answer we might give to a particular MQ. As Quilty-Dunn notes:
[T]he thesis that perception delivers representations couched in the same discursive format as cognitive representations offers to explain how some perceptual representations feed so quickly and effortlessly into the updating of beliefs and the rational planning of action; the commonality of format would allow cognition to act immediately on the outputs of perception without any intermediating translation mechanism (Quilty-Dunn (2020); 809)
We would expect different answers to MQs couched in terms of shared representations depending on whether we were asking about iconic or discursive representations, and whether we were focused on issues of format or architecture. Again, this isn’t a point specifically about whether we should adopt this form of sensory pluralism. The worry is that such views reveal the range of possible choices we have when theorizing about perceptual representations, and these choices matter for how we assess any particular MQ.
In addition to these important questions about representational format and architecture, there are even more fundamental issues to worry about. Consider the pluralistic view of representation recently defended by Nick Shea (2018). As he makes clear, there are multiple choices we can make about how to understand representations, and this can often lead to a multitude of distinct, cross-cutting answers to questions about representational content, and none seem especially privileged. A parade case—one so well-worn that it borders on philosophical cliché—concerns how to understand the representations that guide a frog’s tongue strike at a nearby fly.6 Is it a representation of a fly? Or one of food source? Or small black dot? Moving small black dot? Small black dot moving in pattern P? Different accounts of the psychosemantics here—tracking vs teleogical vs instrumentalist theories—will supply distinct answers to these questions. And Shea makes a convincing case that for some explanatory contexts one or the other of these approaches will be most salient and explanatorily useful. This suggests at the very least that we should be sensitive to the possibility that our choices of representational theory will play an outsized role in how we might answer any particular MQ (where instead of flies, we might wonder if the subject is representing cube, not-a-sphere, object-with-straight-lines, etc.).
Finally, I will just note that similar choice points arise for the conceptual level, where again, we find a number of central approaches to concepts that would seemingly influence conceptual formulations of MQ. Are there distinct visual and tactual concepts of cube and sphere? Are they multimodal or amodal? What are their possession conditions? These questions will turn on our theory of concepts. For Matthen (2005), sensory concepts are nothing but the result of a sensory sorting process, one that could presumably be shared by many systems (i.e., do visual and tactual systems sort cubes and spheres into the same categories or not?). The phenomenal characters associated with these sorts are internally conventional signs distinct from the concept itself. Such a view would suggest certain classes of answers to various MQ formulations. A more robust notion of concepts—ones where concept acquisition was a distinctly cognitive achievement—would presumably suggest different answers. Like for sensory individuation and representation, these competing concerns naturally lead to a kind of pluralism about concepts (Machery, 2009).7 Our choices here would immediately influence how we answer any particular MQ.
In each of the sections above, I highlighted recent pluralistic approaches to these various debates. I happen to find many of these approaches plausible and engaging, and thus likely to generate a multitude of plausible responses to any particular MQ. That said, one might reasonably reply that this is only a byproduct of these forms of pluralism, and so long as we avoid such views we should be able to provide more grounded answers to our MQ. This response is only partially right. In each case, the pluralist approaches arise as ways of reconciling the fact that there are numerous different approaches available for each of these debates, and the evidence for any one univocal view is lacking. It follows that in such contested spaces there will be a host of unified accounts on offer. The critics is right that if we happen to settle on some set of these, then this will in turn constrain and inform our answers to MQ. But notice that now it is even more clear that the answers we get from any particular MQ are determined by our prior commitments, and not the other way around. This is not what we initially took the MQ to do.8
3.3 Psychological explanation
The final fundamental category I want to explore concerns our choice of framework for psychological explanation. For instance, I am thinking here of the big picture choices that underlie our assumptions about what it would take to account for a certain behavioral capacity at all. As we noted earlier, Ferretti (2018) makes the extremely plausible claim that the two visual-streams model should inform how we understand the potential answers to MQ, because it suggests at least two dissociable systems that can be legitimately termed vision. I think this is right. But now consider some even more fundamental issues that are often tacitly assumed by researchers in these contexts. Consider a Gibsonian or Neo-Gibsonian about perception, someone who thinks of perceptual capacities as essentially active, coupled engagement with the world. Such scholars will have a distinct set of assumptions and methodological criteria of evaluation for any particular formulation of MQ (Gibson, 1966; Hurley, 2001; Noë, 2004; Thompson, 2007). These will differ in many important ways from the traditional computational or mechanistic views that posit and evaluate sensory representations and look for computational solutions to the various puzzles of interaction.
As above, it’s not just that there are lots of different options here. Some of the most plausible accounts—those which focus on psychological mechanisms—will have the possibility of multiple, cross-cutting answers built into their very formulations. For instance, mechanisms and their associated functions are usually taken to be determined in part by the explanatory context. For instance, if we start with a larger-scale phenomena to be explained, we could in-principle individuate the component mechanisms in several different ways. This is plausible in part because any smaller causal structures can always in-principle play important roles in several different mechanisms (Bechtel, 2008; Craver, 2009). This is a more general feature of mechanistic explanation. Suppose we are trying to explain automobiles and their operation. There will be explanatory contexts in which it can make sense to treat the steering wheel, steering column, axles, and wheels as a single system, playing a single functional role (determining in which direction a car goes). And of course, there are other contexts in which the individual differences between these parts will be more salient. Something similar is plausible with Molyneux. For some contexts, the physiological mechanisms that define touch and vision and spatial awareness and so on will be drawn in one place, but for other purposes they may be more narrow or broad, including or excluding different things (as Craver (2009) says, we will always have a choice between ‘splitting’ and ‘lumping’). These sorts of worries are if anything amplified in neuroscience contexts, given the pervasive evidence that neural regions often play multiple functional roles (Anderson, 2010, 2015).
Again, the point here isn’t the conditional claim that, if we are mechanists about psychological explanation, then there will be, in-principle, multiple plausible answers to MQ. This is true, but not my main point. Likewise, my point also isn’t the (also true) claim that our answers to MQ could, in-principle, differ depending on whether we are enactivists or computationalists. The point is the more general observation that any specific version of MQ is always going to be framed in terms of more basic assumptions that will critically influence how it’s answered. Since MQ sits far from any of the foundational issues, there is a potent asymmetry. This matters in part because it isn’t just the ground level fundamental issues that play a role here. Those fundamental choices plausibly influence most of our theorizing. The big problem for MQ is that many of our reasonable middle-level commitments—how we think about concepts, sensory modalities, perceptual content, and capacities of discrimination and recognition—will also strongly influence our answers to MQ and not the other way around. That is, while our independently held view of concepts or perceptual learning can make a difference in how we answer a particular MQ, it isn’t the case that behavioral data concerning any particular MQ study will, for instance, settle issues about the nature of sensory concepts or perceptual content. It is this fundamental asymmetry that makes the framing of MQ more contingent on our guiding assumptions, and the answers less important in settling any more fundamental debates.
4 What about reflective equilibrium?
A natural response to the above line of thought may be to downplay the significance of my claims. After all, everything in cognitive science will depend on the basic taxonomic principles, our account of representation, and our favored explanatory framework. It is difficult to imagine any questions about psychology, much less perception, that wouldn’t be influenced by these other more fundamental choice points. To say that MQ sits at the more specialized realm is thus not such a terrible charge.
I think this is a perfectly reasonable reaction as far as it goes. And one that accurately reflects the state of play in contemporary debates about cognitive science. Almost all the work I come across these days makes clear in the early going the important assumptions that guide everything that follows. This results all too predicably in some disconnections between different subfields in cognitive science, where those working (say) in 4E frameworks can find it difficult to engage critically with traditional computationalists, and vice versa. It should not be surprising then that such fundamental choice points would influence our answers to any particular MQ. What we do in practice is try to achieve a kind of reflective equilibrium. We hold fixed some foundational commitments, engage in our investigations, and recalibrate in the face of our findings. No single answer to a specific MQ would settle a foundational issue, but such a finding in conjunction with our other investigations and commitments will give us the means to evaluate and determine the answers to both the foundational and more sophisticated questions. For this reason, MQ can still function as a useful intellectual tool, and a means of formulating new questions and experiments, even if the answers to these questions will always be formulated relative to a host of more fundamental assumptions.
The fundamental issues are fundamental for a reason, and of course such choices will influence how we conduct inquiry. That’s what it means to call them fundamental. Still, I think even this fact is less supportive of MQ than one might think. For one, it acknowledges the extent to which MQ is beholden to our theoretical choices. Not just how we answer it, but even how we frame the question depends significantly on the foundations. This is a corrective for those who might have thought finding pristine experimental evidence concerning a particular MQ would settle some of the hot-button fundamental questions. More importantly, MQ doesn’t just depend on the deep foundations. Many discussions in cognitive science can proceed with nothing more than a minimal set of commitments (there are representations; there’s some natural distinction between perception and cognition; perceptual learning is real, etc). But MQ, especially any specific formulation, requires a host of intermediate commitments, all of which seem crucial to the kinds of answers we’ll get. This relative sensitivity to underlying choices applies especially to sophisticated and theoretically complex questions like MQ. This is reflected in the sheer variety of distinct formulations found in the literature, and the many different contexts in which MQ finds purchase. Such specific formulations, individuated by subtle distinctions and clarifications, will naturally be more sensitive to our prior commitments than other less specific questions.
All of this said, I allow that if we are clear about our commitments and our formulations of a specific MQ, then the possibility of finding an answer arises. But how we might go about answering any of these well-formed questions will crucially turn on those commitments. And this means the value of addressing MQ will vary as our commitments vary. My own sympathies are with a pluralistic taxonomy of sensory modalities and their borders with cognition and emotion (Fulkerson, 2014a, 2020; Khalidi, 2023; 2017; Pessoa, 2013), a broadly pluralist, instrumentalist account of representation (Egan, 2014, 2020; Shea, 2018), and a broadly mechanistic account of psychological explanation (Bechtel & Bich, 2021). For me, there will be in-principle many reasonable and genuinely explanatory, but cross-cutting, answers to most MQs. Determining answers in these contexts will almost always be an empirical question addressed within a specific explanatory framework.
5 Conclusion
Molyneux’s Question faces two strong worries that threaten to undermine its significance. For one, the question can be made precise in many different ways, spawning numerous distinct versions that seem to admit of a host of plausible answers. Second, even if we settle on a specific formulation, the answers we derive will depend strongly on our more fundamental commitments about how to individuate the senses, determine sensory content, and explain psychological capacities like recognition and discrimination. This paper has been an attempt to sketch a defense of this second line of thought.
While questions in cognitive science do generally depend on our more fundamental choices, MQ seems especially sensitive to a wide range of intermediate choice points. Where does that leave us? My own view is that we should not think of MQ as a question that by itself plays an important role in the normal course of cognitive science investigation. Instead, it functions more in the way that thought experiments like Twin Earth and Mary the Color Scientist function, as important intellectual tools that help us be creative and thoughtful about how to think about difficult issues in cognitive science (Nida-Rümelin, 2024). Reflecting on Mary and asking whether she learns something new when she exits the room can raise interesting theoretical questions and inspire reflection on recognitional abilities more generally, but nobody thinks it would be a good idea to look for the answer to this question empirically (setting aside the practical impossibility of finding a subject who knows all the physical facts). This is in-part because there are just too many confounds and unconstrained possibilities that make Mary’s actual actions upon exiting the room less interesting as an actual experiment. When Mary says “Oh, that’s what red looks like,” that utterance will need to be interpreted against a background of assumptions about perceptual experience and learning. This utterance alone wouldn’t settle the question of whether physicalism was true or not. I think the same is true for MQ. Suppose the newly sighted subject can tell the cube from sphere (by correctly pointing at the correct one when asked, which is which). Does that behavior, on its own, constitute the answer to Molyneux? Would it settle any of the important questions about the relation between the senses, spatial or shape content, or recognitional capacities? My view is that it would not. At least not on its own. And for that reason, we shouldn’t care (that much) about the answers to Molyneux’s Question.
References
See e.g., the general introduction to Glenney and Ferretti (2020) and especially its second chapter, Goodman (2020).↩︎
The interested reader can get a solid foundation of the history from the papers in Glenney and Ferretti (2020).↩︎
I use “MQ” to refer to the class of questions related to or inspired by Molyneux rather than to pick out any particular formulation of the question.↩︎
As noted by Matthen (2020), the even earlier version of the puzzle attributed to Abu Bakr Ibn Ṭufayl was also importantly different in nature.↩︎
Other examples at the highest level might include debates about how to distinguish intentions and motor representations (what Butterfill and Sinigaglia 2014 call the “interface problem”; Butterfill & Sinigaglia, 2014; Sinigaglia & Butterfill, 2015) and questions about whether prisoner’s dilemma studies have independent value for assessing theories in social psychology (Northcott & Alexandrova, 2015). I am thankful to a referee for suggesting these examples.↩︎
The case and its long history is discussed in detail in Millikan (2024).↩︎
Machery specifically defends eliminativism about concepts, but he also endorses that we adopt several alternative conceptions that are more in line with empirical findings in cognitive science.↩︎
I don’t mention it here, but similar arguments and concerns could be made about the different conceptions of perceptual learning on offer in the literature (Connolly, 2019; Jenkin, 2023; Stokes, 2021).↩︎